
Finding the Most Popular Books of the Past Decade
How to collect custom bestseller book lists using the New York Times API.
Introduction
Working at a bookstore, it’s important to know which books are going to sell. The New York Times Bestsellers list is one of the most authorative rankings of bookselling out there, and luckily you can customize your own book listing depending on what information you want to know. On its list, the New York Times provides how many weeks the book has been on its list, the publisher, and the author. This information is helpful to me to get an idea of what books are going to be more likely to sell, what publishers and authors I should buy from, etc. It could be helpful to you in knowing what books you want to read! Let’s begin.
This is what the NYT Bestsellers list looks like on their website.
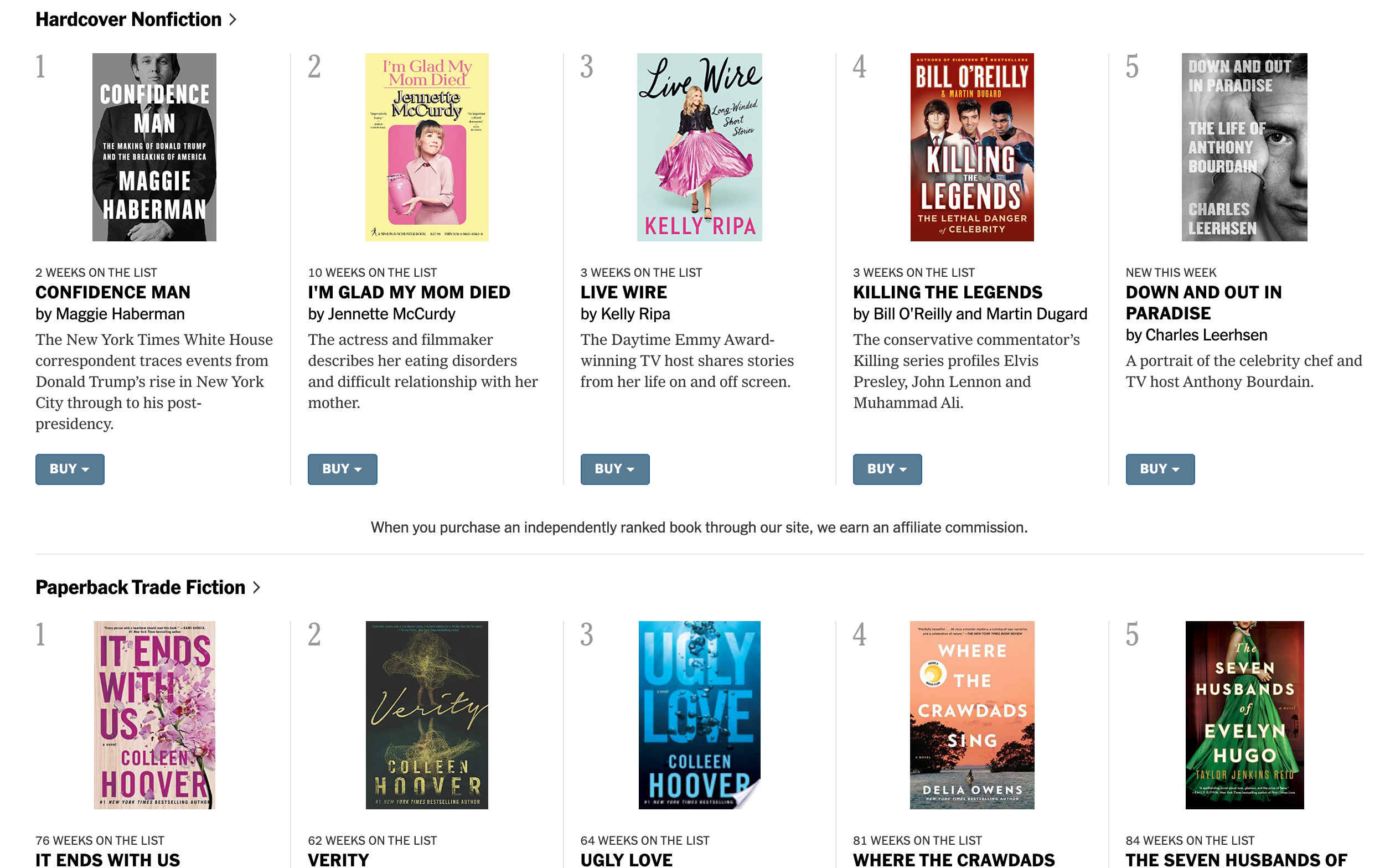
Our goal is to get this information in our own dataframes, and personalize the lists for our own use. For me, this means getting the NYT Bestseller list for hardcover and paperback fiction for the month of October from the years 2012-2022.
Get Your API Key
In order to get your NYT API key, you’ll need to start a developer’s account (good news, it’s free!). You can do that now by following this link. All you’ll need is your first and last name, email, and a password that you create.
Now, follow these steps:
- Once you’ve created your account, you can sign into the account here, using the email and password you created.
- Afterwards, click on drop down menu under your name in the top right corner and select “Apps.” In order to get your API key, you’ll need to create an “app.”
- All you need to do here is select the button in the top right corner that says “+ New App,” give your app a name and description, and then choose which API you’d like to enable. In this case, you’ll want the Books API, but notice how many other APIs that the NYTs offers!
- Now, save the changes you’ve made and voila you have your API key.
Find the Required Endpoint Parameters
On their website, the New York Times has a nice overview of the Books API that you can find here. Basically, there are two main kind of lists that the Books API provides: rankings according to how many books have been sold or a list of book reviews. We’ll be focusing on the rankings in this article.
When obtaining a list with your API key, the url will look something like this:
my_url = "https://api.nytimes.com/svc/books/v3/lists/current/hardcover-fiction.json?api-key=yourkey"
The two main features that we’ll want to pay attention to in this url are the list data, or the information that comes after lists/ in the url. According to the website, “the lists/{date}/{name} service returns the books on the best sellers list for the specified date and list name.”
{date}
If you want the current NYT Bestsellers list, you just put “current” in the date section of the url. However, if you want the NYT Bestsellers list for a specific date, you put in the date in this format: YEAR-MONTH-DATE. For example, 2012-05-30 for May 30, 2012.
{name}
The New York Times has lists for books in different formats (hardcover, paperback, and e-book) and genres (fiction and non-fiction). In order to get a list of a cetain format and genre, you would need to put in one of these values:
- hardcover-fiction
- trade-fiction-paperback
- e-book-fiction
- hardcover-nonfiction
- paperback-nonfiction
- e-book-nonfiction
Gather the Data of Interest
Once you have decided which formats, genres, and dates you would like to gather data on, it’s still a little tricky getting the data into the dataframe that you format that you want. But don’t worry, we’ll walk you throught the process! We’ll be using our API and requests.
Request URL
Use the code below to request the URL (insert your own API key into the URL).
my_url = "https://api.nytimes.com/svc/books/v3/lists/current/hardcover-fiction.json?api-key=yourkey"
r = requests.get(my_url)
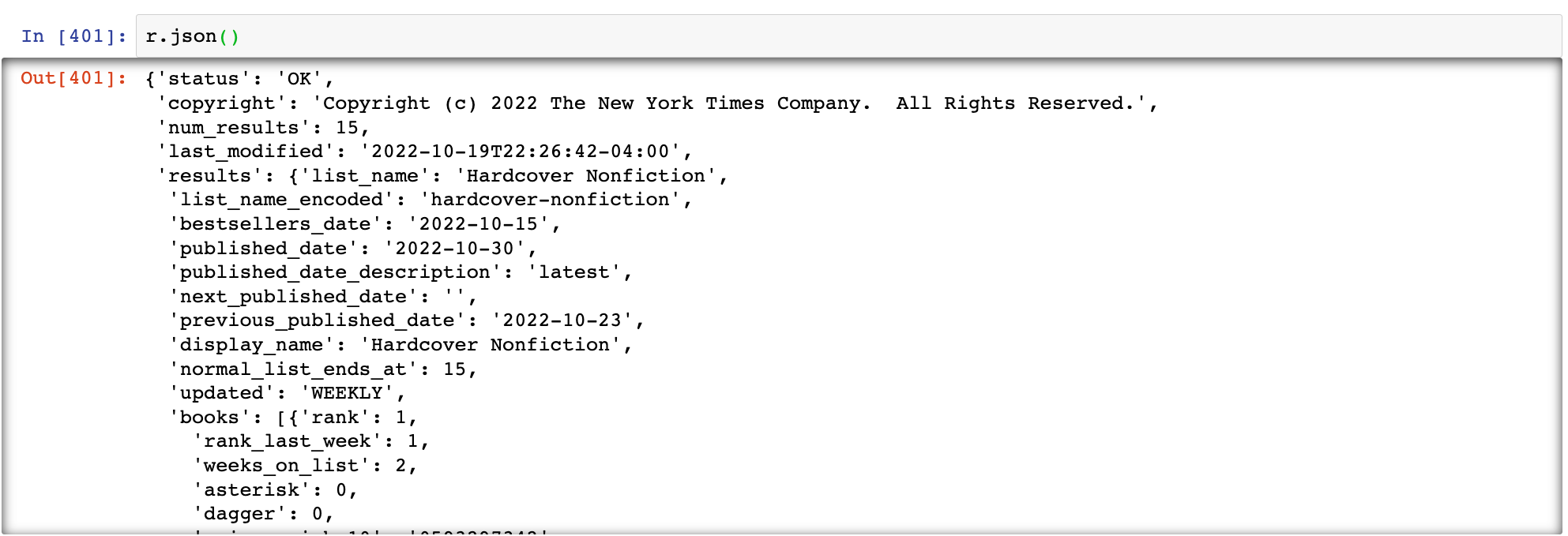
The r.json() should look something like this:
Create Dataframe Using Pandas
Make sure you have pandas imported, and then create a dataframe by saying pf = pd.DataFrame(r.json())
The resulting dataframe will look something like this:
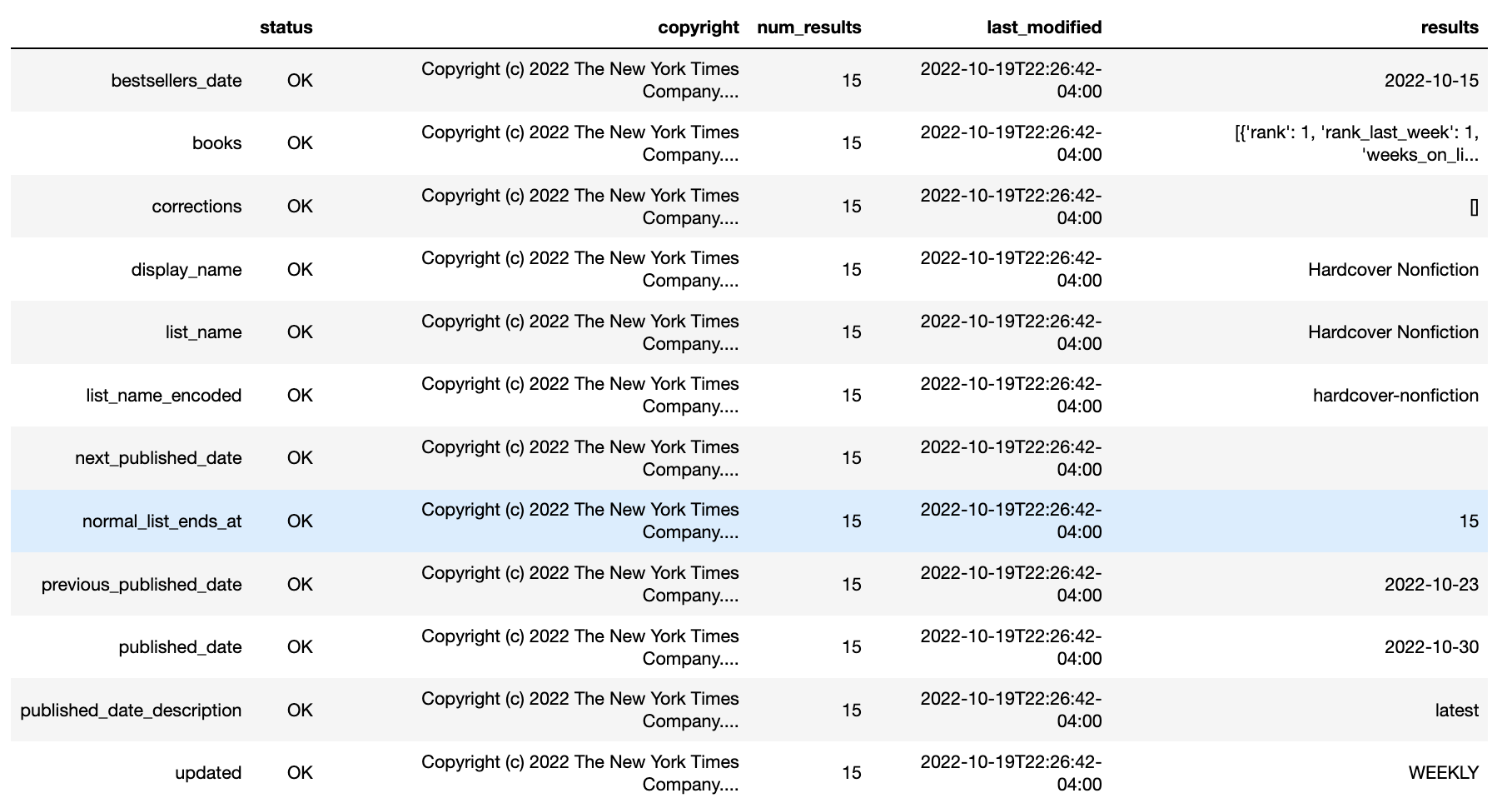
As you can see, the dataframe does not immediately show us the information we want (book rankings, publisher information, title of book). All of this information is instead stored inside the “results” section of the row “books.” In order to access that information, we’ll have to do a little manuevering.
- Separate books from the rest of the dataframe with
books = pf.iloc[1] - Now, create a dataframe of the “results” row within books with
pd.DataFrame(books['results'])
If we look at the dataframe we just made, it should look like this:
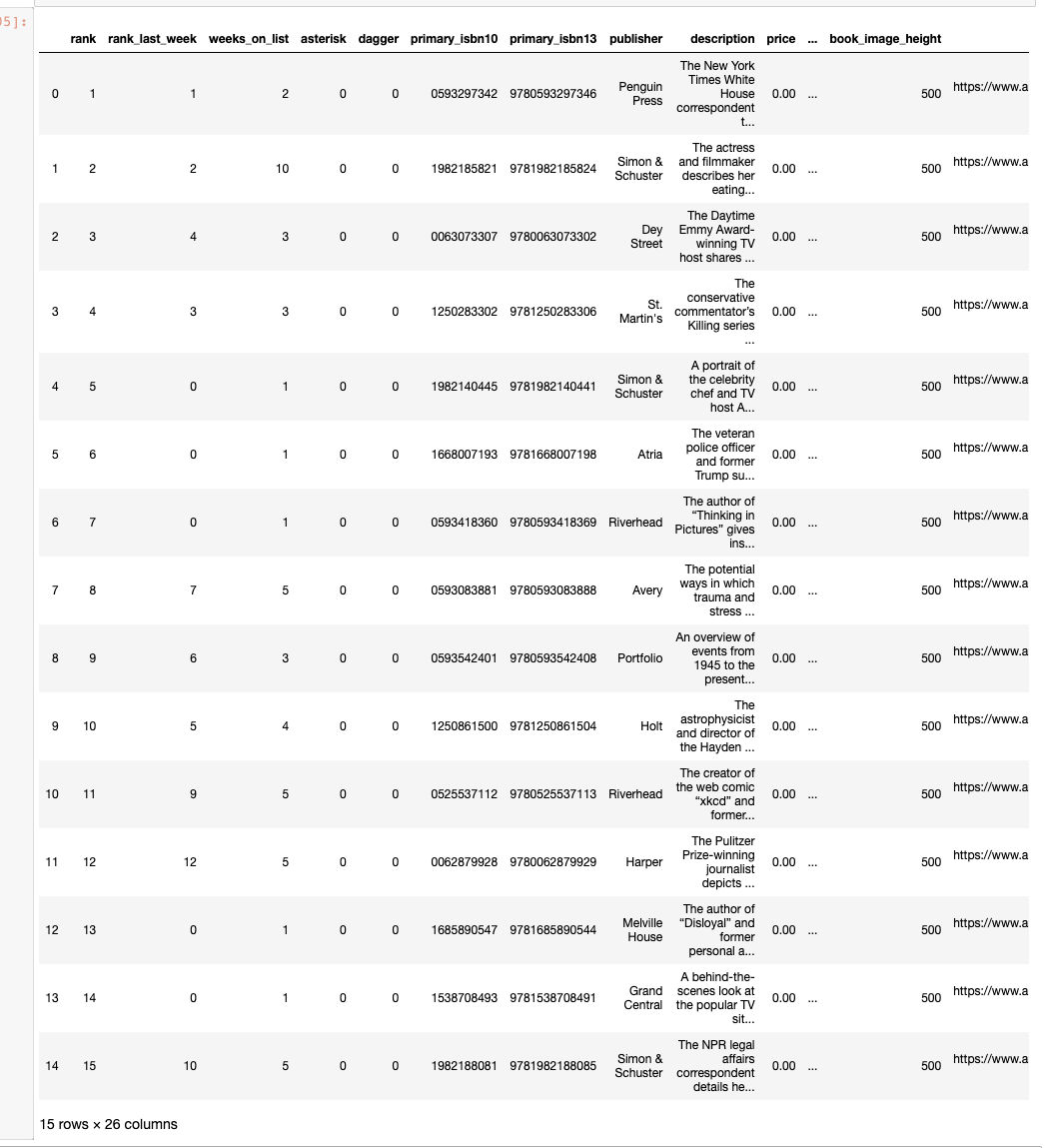
The dataframe is too big to see completely within jupyter notebooks, but if you want to look at titles that are on the Bestsellers list, you can simply say your_dataframe['titles'], and it will give you the list of titles on the list for that week. For example, for our list (Oct 21, 2022, hardcover, non-fiction), the list is:

Personalize Data
The data I would like to gather is all the fiction bestseller lists for both hardcover and paperback books for the week of October 21 from the years 2012-2022. In order to do this I put in the date that I want (YEAR-10-21) and either ‘hardcover-fiction’ or ‘trade-paperback-fiction’. Each separate list will contain only about 15-20 different titles, so I then put all these separate dataframes into a list, and then concatenate that list into a complete dataframe: bestseller = pd.concat(frames)
The resulting dataframe “bestseller” looks like this:
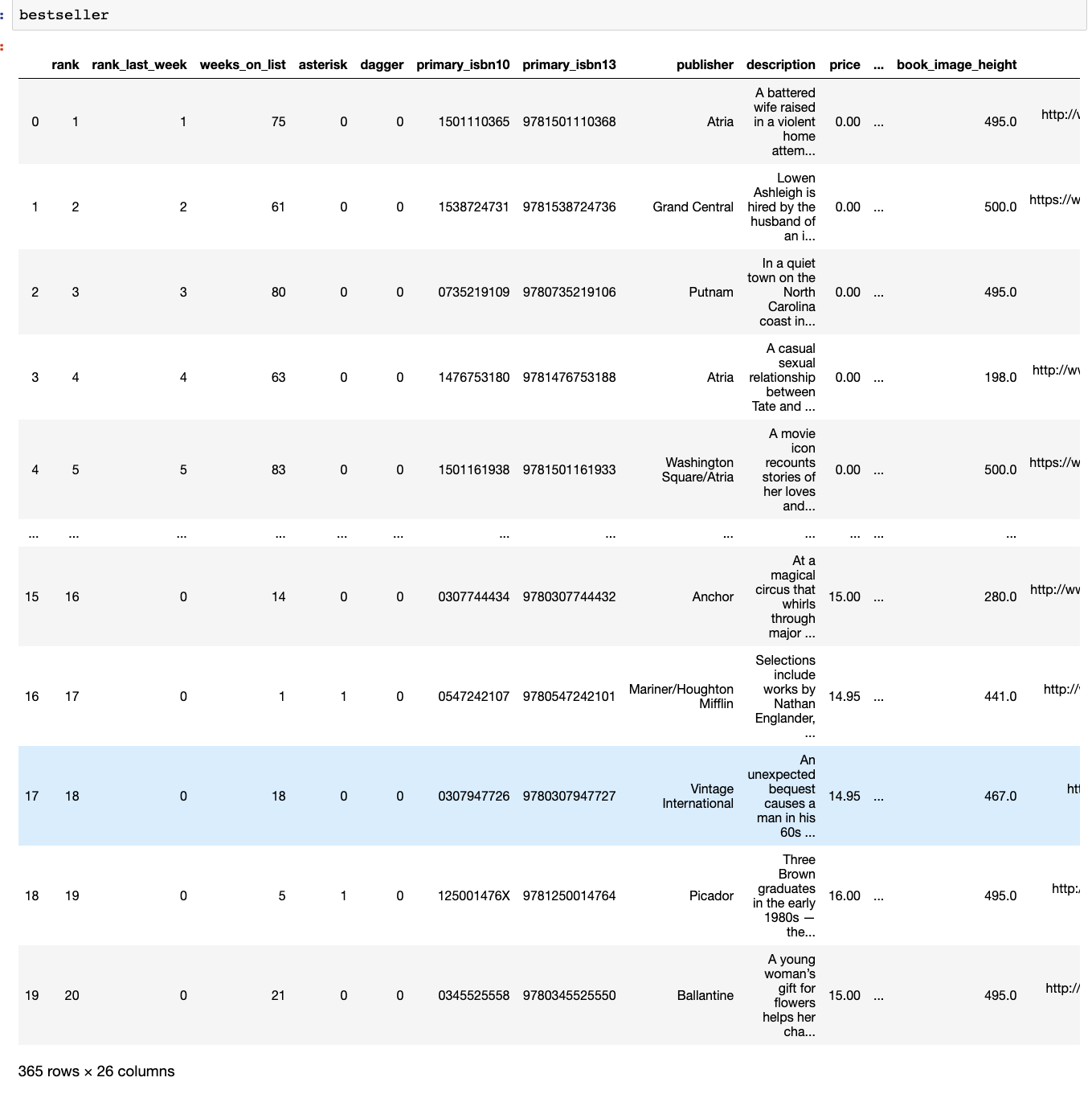
There are 365 rows and 26 separate columns. Later on, I might want to remove some of the columns that aren’t necessary, but for now I am happy with my dataframe.
Is this ethical?
A quick note on if this way of obtaining data is ethical or not. In the NYT terms and conditions found here, they say that API keys should not be used to any commercial use or in anything that is illegal. As I am not using the API key in anyway to get money, and I am not breaking the law, it is ethical to use the NYT API key to get this information.
Conclusion
In this post, I showed how you can access a NYT API key, how you can use that key to get various NYT Books Bestsellers list, and how you can personalize the data you want within those Bestsellers lists. This information could be useful to see what books have been the most popular over time, what publishers are most likely to have books on the bestsellers list, and what books you might be interested in reading/buying/selling. Let me know in the comments if you have any questions regarding accessing information within these lists. In my next post, I will provide an exploratory data analysis of this data.
Here’s a link to my github repo link